


The Power of Scientific Software and HPC: Accelerating Discovery
Introduction:
Now that you know more about the anatomy of a supercomputer, let me tell you why these massive machines are useful in the first place. You see, we live in a world with incredible challenges. After all, if you really think about it, we are the only species that puts itself under a microscope and is trying very hard to understand not only our place in this universe but the universe itself. We have surrounded ourselves with satellites orbiting the Earth taking high resolution pictures, gathering data about our atmosphere, about our oceans…to truly understand how our planet evolves and what is our impact on it. Scientists have now access to incredible amounts of data and are trying to make sense of this. That’s where supercomputers come into play. If you want to tackle large problems, you need large computers.
Table of Contents
December 11, 2024.
The following drawing summarizes what we generally do when we use a computer to solve certain problems: in essence, you first start with an idea or a problem you are tackling, then you express it using source code, then you run it and wait for the results. If you are happy with the results, then you can proceed with writing the research paper or start production of your product.
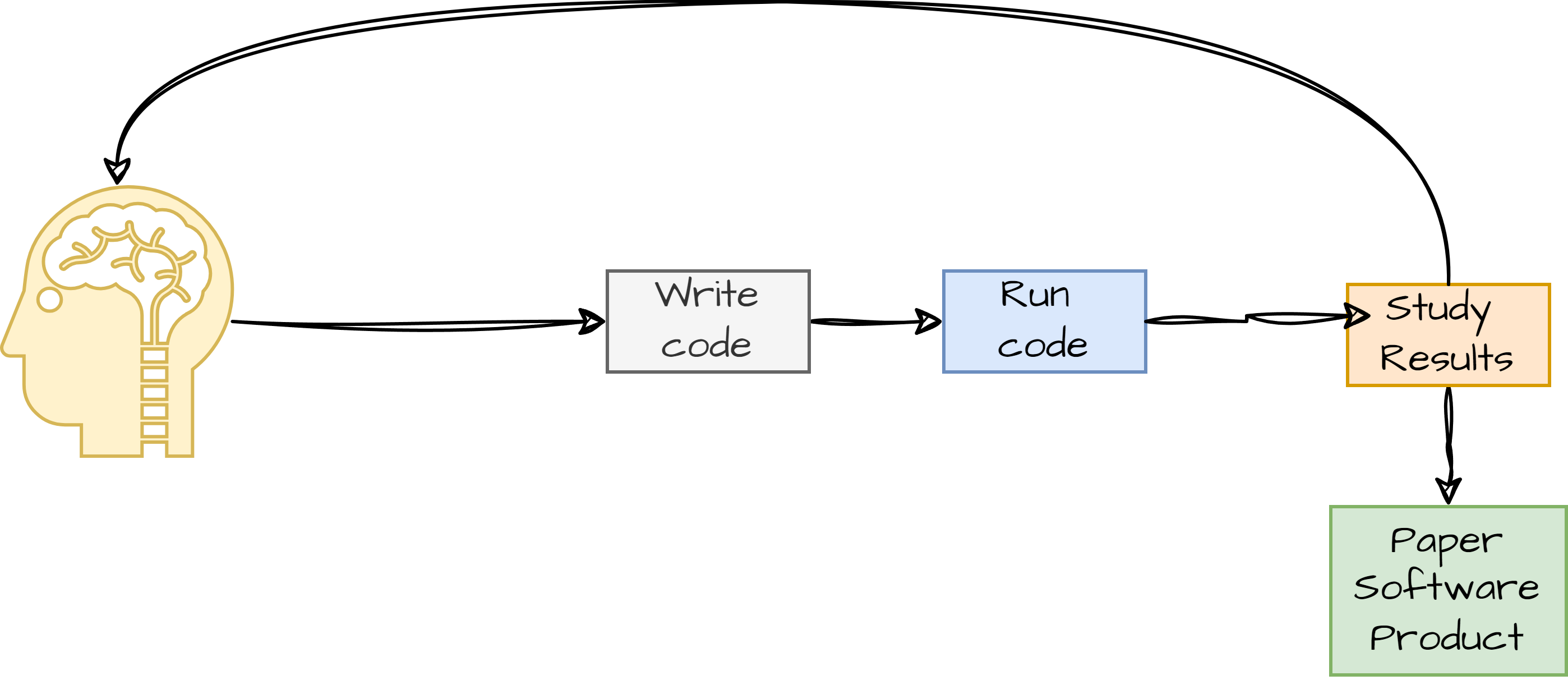
The Supercomputing Application Service (SAS) team at LuxProvide is there to help our users pick all the necessary tools to express their ideas (with various programming languages) and all the necessary libraries and runtimes to efficiently run their code at scale.
The following equations and fields are at the very core of our understanding of the world:
- Schrodinger’s equation is at the heart of the best-known theory of physics so far: quantum mechanics. Many software are solving this equation to study matter at its fundamental level.
- The all-pair N-Body problem is a set of equations that are at the core of a field known as Molecular Dynamics (MD) which are used to understand how planets, galaxies move and evolve into space but also used to understand the physical movement of atoms and molecules which is key in chemical physics, biophysics and material science.
- Navier Stokes equations are at the centre of a field known as Computational Fluid Dynamics (CFD) or in plain English the equations that are used to understand how fluids behave.
Their implementations represent in one form or another are at the very core of scientific computing. To help out MeluXina users, Luxembourg’s high-performance computer, we provide several software stacks for them to use from day one on the system. Scientific software are not your usual software in the sense that not only they are very complex to install because they rely on many dependencies but also because chances are the users will not fine-tune them for the system. To ease the life for our users, we provide what we call the MeluXina User Software Environment (MUSE) with more than 400 ready-to-be-used software ranging from compilers, programming languages, numerical libraries up to end-user applications. When you manage so many software, you need proper automation to help you out. In the case of MeluXina, all our software stacks are managed using EasyBuild, a python-based tool which enables you to write some sort of recipe for compiling software, specifying the dependencies, the compiler flags to use for compilation and linking. Alongside EasyBuild, we use another tool called ReFrame for automating the performance regression tests on MeluXina. You see, when you have a system such as MeluXina, you must ensure that performance of the machine does not degrade over time and/or when you modify the system (like upgrading the GPU drivers). So, we use a selected set of tests that we run daily to ensure this does not happen.
Our users are mostly scientists and researchers in various domains. It takes a researcher to truly understand another researcher and really support her/his scientific endeavours. That is the main reason why you will find a high proportion of Ph.D level people within the company with different backgrounds in science along with a strong background in computer science as well. We clearly do not need to be expert in all the research domains obviously but we need the scientific mindset and background to translate what our users are trying to achieve and try our best to support them on MeluXina.
“You know you are a managing a world-class supercomputer when you have a Nobel prize winner running on your machine”.
One of our duties is to evaluate at the technical level all the projects coming from the EuroHPC share and what a shock when we realized that we had a very famous user such as Prof. Giorgio Parisi from University of Roma La Sapienza, Nobel laureate in Physics in 2021 for his fundamental contribution to the theory of complex systems. In 2022, together with his co-authors, they ran 1 year worth of simulations in just a couple of months. These simulations were at the core of two research articles published in 2024, one in Computer Physics Communication and the other one in Nature.
Performance Debugging
We are part of several EU-funded projects, one of which is called EPICURE. The goal of this project is to provide high level support to users; high-level in this case means that we help them on profiling their applications and improve their code. Reasoning on the performance of software is commonly known as performance debugging. One key objective of the project is to ensure that the software is using the hardware at maximum efficiency. This is far from being trivial and requires a deep level of expertise in pure software engineering, compiler/runtime internal knowledge, knowledge at the operating system level, and high-performance communication libraries to mention a few. Below is a layered view of where the SAS team can intervene in order to improve the software for our users.
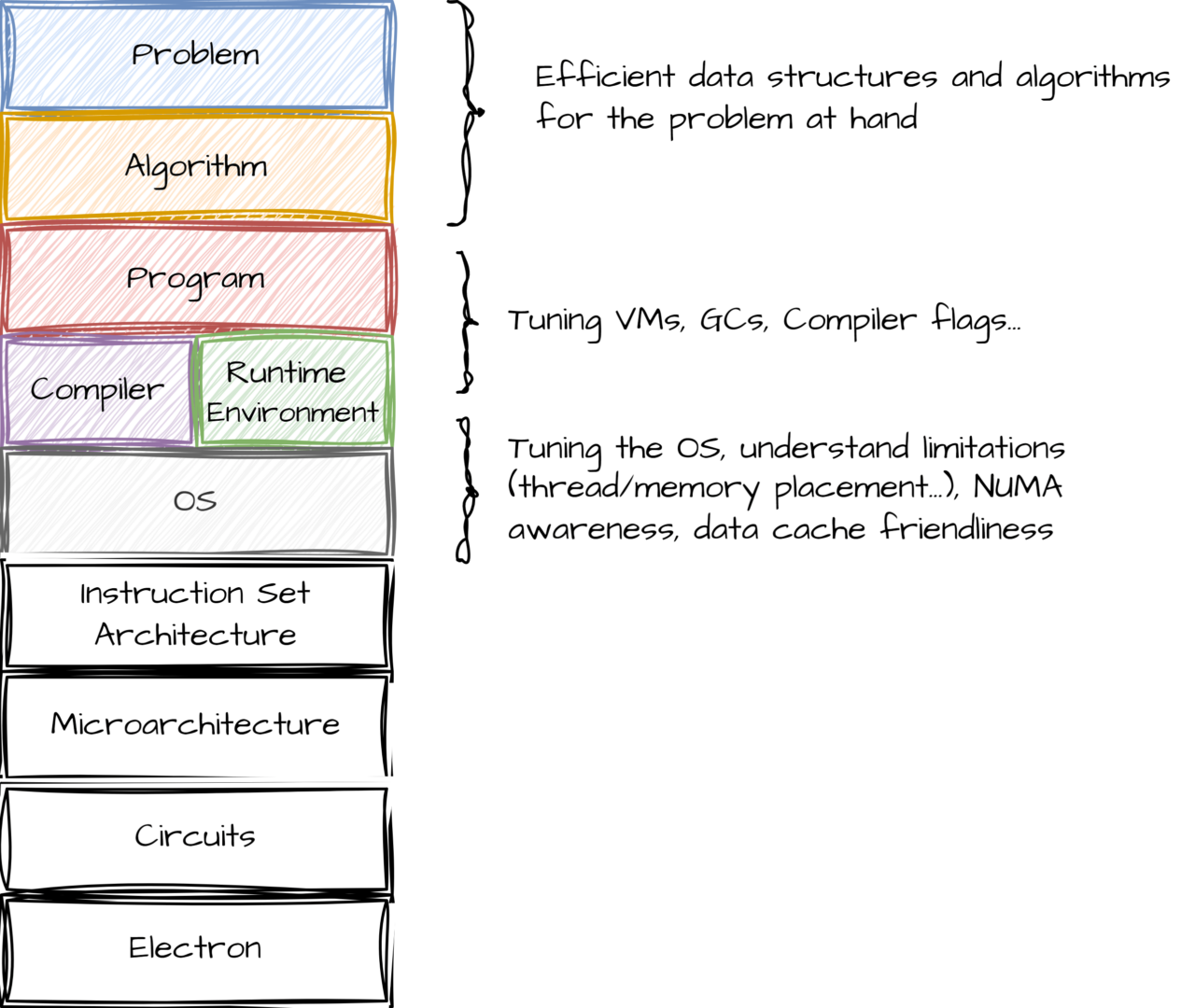
Any software is expressed in a source code, but the source code is not executable per se because the hardware does not understand what the source code is. The only thing a machine understands is machine code. To transform source code into machine code, you basically have two paths: either use a compiler that directly transforms source code into machine code or use what it is called an interpreter that transforms source code into an intermediary form on the fly and then will transform this intermediary form into machine code. Some compiled programming languages are Fortran (which is a contraction of Formula Translation), C, C++, Rust and Chapel. Interpreted languages examples are Python, Julia and R.
Let’s take the CPU model present in our CPU partition, the AMD Epyc 7H12, a 64-cores processor. But do you actually know the type of processor it is ? It is an out-of-order superscalar with speculative execution processor. I know, it’s a mouthful, let me explain what it means in simpler terms:
Out-of-order means that the instructions are executed in such a way to maximize the number of instructions per cycle (per clock cycle), to keep the processor busy. Superscalar means that the CPU is executing multiple instructions in parallel and leverages what is called instruction level parallelism (ILP parallelism). Speculative execution means that the processor has what is called a branch predictor, a specialized hardware part of the processor which tries to guess which instructions are likely to be executed once you are in a conditional branch. If it guesses right then it can prefetch in advance some instructions prior to their execution and gain some time but if it guesses wrong, then it has to invalidate the whole cache line and re-fetch the instructions thus losing precious time and impacting the overall execution time. These features of modern processors cannot be swept under the rug if you are serious about performance. Just like a race driver needs to know the limits and capabilities of her/his car, a serious scientist should be aware of the limits and capabilities of the processor she/he is using for scientific computations to best take advantage of the raw power.
Scalability and parallelism have their own limitations and “laws”; some brilliant minds having worked deeply around the design of processors came out with great insights when it comes to executing instructions on a processor. The following laws and conjecture are still very valuable today:
- Amdhal’s law
- Gustfason’s law
- Gunther’s conjecture
Amdahl’s Law states that the speedup gained by increasing the degree of parallelism of an application is limited by its serial part. This law assumes that the serial part of the application stays constant, which is actually not always the case. Speculative, ahead-of-time and out-of-order executions can speed up the application without turning a sequential code into a parallel one. Skepticisms around Amdahl’s Law pushed John Gustafson to reevaluate it . Amdahl’s equation makes the implicit assumption that the time spent on parts of the program that can be done in parallel is independent of the number of processors, which is virtually never the case. In practice, the problem size scales with the number of processors. Gustafson’s Law enables speedup gains when more core are added, whereas Amdalh’s Law puts an upper bound on the speedup gains due to the fact that it assumes that the time share of the sequential part will stay constant as the number of available processors increases. Gunther introduced a conjecture called the Universal Scalability Law, a reevaluation of Amdahl’s law which captures the impact of the overhead induced by synchronization primitives and other sources of delay which are not inherent to the algorithm but needed by the application to maintain a coherent state (e.g., synchronization protocols between cores such as cache coherence protocols). Gunther’s conjecture nicely captures the behavior of applications in reality; when an application runs over an increasing number of cores, it stops gaining performance after a certain number of cores and even has a decreasing performance as more cores are available.
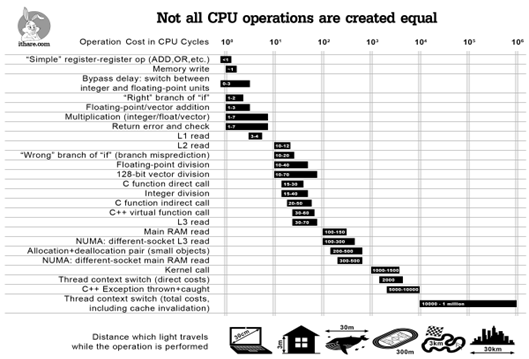
Not all CPU instructions are created equal; in the following table you can find the latency of the instructions that make up a CPU along with an analogy of the distance that light would travel given this latency. This gives you an idea that the choice of instructions that make up your software can have an enormous impact on the overall runtime and serves as a hard reminder that proper software engineering is not an easy task.
The Need to Raise the Level of Abstraction
John Backus, the father of Fortran and Turing award winner for this key contribution was the first proponent of moving away from the so-called Von Neumann bottleneck in his Turing lecture. John Von Neumann was a scientist who basically shaped the architecture of computers as we know it; a CPU has an ALU (Arithmetic and Logic Unit), a memory bank, an IO unit…but inherently this type of architecture has limits when it comes to scalability and performance. What he meant was that we (programmers) should also move out from Von Neumann programming languages and go towards a more functional way of expressing our computations; he provocatively pushed us to rethink the way we come up with more expressive programming languages. Bear in mind that his article was published in 1978 but yet, his insights are somehow still valid today.
Alan Kay, also Turing award winner for his contribution for the programming language Smalltalk and the advent of Personal Computing (PC) shares the same view as John Backus and will go even further to say that “we should be programming in terms of high-level specifications, feed that to a supercomputer and let it generate an efficient implementation for the system at hand”. This sentence right there represents one of the holy grails of computer science. Today’s software suffer from obesity and are seriously bloated. Windows or the Linux kernel are massive million lines of code and making sense of just the operating system is a tremendous effort.
Kenneth Iverson, another Turing winner, came with an incredibly expressive “language” called APL, which is probably the first real array-oriented programming language. I put it in quotes because initially his language was never meant to be executable and was more to teach mathematics for his students. Yet, in his famous Turing lecture, Notation as a Tool of Thought, he underlines how a great notation is incredibly powerful to express ideas. There are many descendants of APL nowadays: J, Julia, Numpy, R, Matlab…which owe a great debt to APL. The J programming language is incredibly powerful once you get past its idiosyncrasies.
In this age of AI, we see a small revolution also happening in the way we write scientific codes and how we run them. Physics-Informed Neural Networks (PINNS) are models that can learn how to derive physics from large amount of data. Are they reliable you might ask? Well, they could if the underlying data is good. Will they replace human beings? That is a philosophical question, my two cents is that they are complementing our toolbox and as any tool, we should use it with caution and always maintain critical thinking. AI models are trained to structure and link data in a high dimensional space. This can be hard to grasp for us as we are not used to think beyond our 3/4 dimensions. What is important is that we can look under the hood of those models and decide for ourselves if they are good tools or not. AI models are still not capable of pure abstract mathematical reasoning. Well, the main reason why has to do with the core foundations of mathematics (set theory, propositional logic…) and these have inherent limitations as well (Gödel’s incompleteness theorems). That is why hardcore mathematicians are trying to re-construct the foundations of mathematics on other grounds (homotopy type theory) to overcome the limitations that Gödel pointed out. As long as this work is not complete, we will still have some advantage over a machine.
About the author

Ready to push the boundaries of digital innovation?
Reach out to us now and let’s make it happen.

ul.px1745022584l@ofn1745022584i1745022584

(+352) 85 99 14

OFFICES
ATRIUM BUSINESS PARK
31, Rue du Puits Romain
L-8070 Bertrange
Luxembourg
MELUXINA
SUPERCOMPUTER
LUXCONNECT DC2
3 Op der Poukewiss
7795 Bissen
Luxembourg